一.Map
java 中的 Map 是一种以键值对存储数据的数据结构,可用于快速查找。 Map 通常 是不保证有序性的(除了 TreeMap ),且一个 Map 内部 一般要包括三个集合视图,key 的集合,value 的集合 ,以及键值对的 Entry 集合,对这三个集合的修改都会直接影响 Map 集合。1
2
3
4
5
6
7
8
9
10
11
12//key 的集合,需要保持互异性 使用 Set
Set<K> keySet();
// value 的集合,不需要保持互异性
Collection<V> values();
// 键值对的 Entry 的集合
Set<Map.Entry<K, V>> entrySet();
//键值对的接口
interface Entry<K, V> {
}
可以看到对于 key 和 Entry 都是用 Set 集合,Set 集合一般有如下特点:
- 无序性:一个集合中,每个元素的地位都是相同的,元素之间也都是无序的(也有有序的 Set)。
- 互异性:一个集合中,任何两个元素都是不相同的。
- 确定性:给定一个集合以及其任一元素,该元素属于或者不属于该集合是必须可以确定的。
二.AbstractMap
1 | public abstract class AbstractMap<K,V> implements Map<K,V> { |
AbstractMap 是一个抽象类,在具体的 Map 的实现类和接口之间定义的一层抽象,为了就是服用一些用的函数。
1 | // 键值对集合 EntrySet 是一个抽象的函数,交由实现类去实现 |
在 AbstractMap 还有两个 Entry 的实现类。
- SimpleEntry 简单的 Entry ,对一个 key 和 value 的封装。
- SimpleImmutableEntry,简单不可变的 Entry, 这个键值对 的 值是不能改变的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public static class SimpleEntry<K,V>
implements Entry<K,V>, java.io.Serializable
{
private static final long serialVersionUID = -8499721149061103585L;
private final K key; //key是final 的
private V value; // value 不是 final 的
...
// 可以进行 setValue 操作
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
1 | public static class SimpleImmutableEntry<K,V> |
三.HashMap
1.Hash 算法
(1)简介
hash 算法是一种可以从一个任何长度的数据中提取出一个固定长度的算法,这个固定的长度就叫做 hashCode ,hash 算法具有如下两种特性:
- 唯一性:同样的输入经过 hash 算法得出的结果都是一样的。
- 不可逆性,不能从 hashCode 得出原本的数据。
- 重复性:对于不同的输入,可能得出同样的输出。
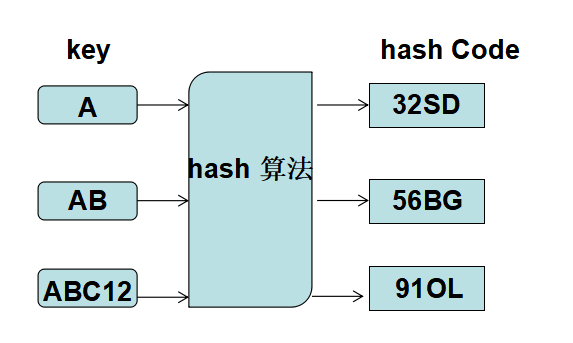
(2)hash Code
在数据查找过程中,最理想的情况是可以不进行记录的比较,就直接得到待查记录。若记录的关键字与存储位置存在某种一一映射关系,那么就可以通过待查记录的关键字,计算其存储位置,直接找到该记录。实现这种对应关系的函数就散列函数,散列函数中就运用到了 hash 算法产生的 hash Code .
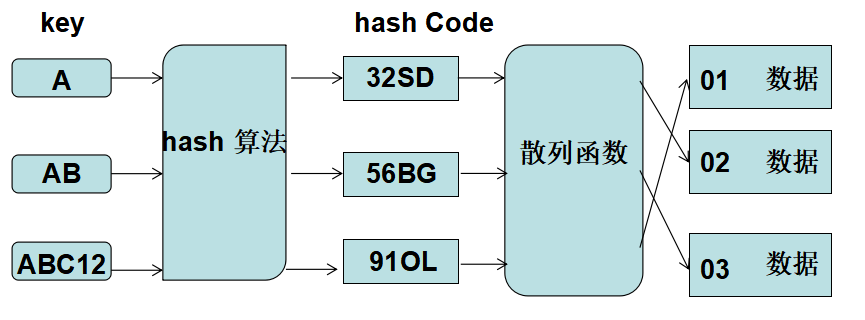
(3)hash 表
hash 查找通常需要维护一个数组,这个数组就叫做 hash table (hash 表 或 散列表)
这个数组元素被称为桶( bin ),当传入一个 关键字 key 的时候,就可以通过散列 函数直接将 key 转为数组的下标。通过下标就可以直接得到对应的数据。
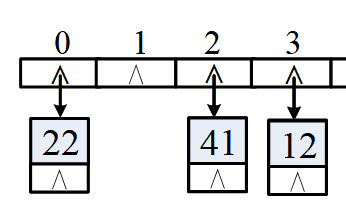
(4)冲突
前面说过 hash 算法具有重复性,因此在 hash Code 上建立的 散列函数也就存在着重复,不是一一对应的关系,出现两个不同的数据拥有在 hash 表中同一下标的情况就叫做冲突。
处理冲突的方式有两种方式:
- 开放地址法: 开放地址又分为线性探测和二次探测。
- 链地址法。
线性探测
思想是:若哈希表的地址区间长度为m,将哈希表看成是一个循环空间,如若冲突就放在数组后一个位置,如果下一个位置已有数据就再往后放。
这种想法的缺点很明显:如果连续序列越长,则当新的元素加入该表时,与这个序列发生冲突的可能性越大。
二次探测
思想是:探测的序列不是连续的,而是跳跃式的,为后续待插入的记录留下空间从而减少堆聚。如若冲突就根据一些跳跃的函数进行跳跃式的探测,如若有数据就再进行探测。
链地址法
链地址法将关键字为同义词的记录链接在同一个单链表中,即数组元素是一个个节点,如若冲突就在这个节点上生成一个链表。
2.HashMap
HashMap 实际上就是基于 hash 表的一个查找集合。
HashMap 的散列函数
1 | // HashMap 维护的 哈希表 |
HashMap 的散列函数没有一个固定的实现,但是基本的思想都在上面的代码中。
- 内部实现了一个hash()函数,首先要对key 的 hashCode() 进行处理
- 该函数将 key.hashCode() 的低 16 位和高 16 位做了个异或运算,其目的是为了扰乱低位的信息以实现减少碰撞冲突。
- 把处理的返回值与 table.length - 1 做与运算(table 为 哈希表),得到的结果即是数组的下标。
(n-1) 就是数组的最后一位的而下标,就像是一个低位掩码,它和 hash() 做与操作时会将高位屏蔽只保留低位,它会导致总是只有最低的几位是有效的,因为就算你的 hashCode() 实现得再好也难以避免发生碰撞,所以 hash () 对 hash code 的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
处理冲突
HashMap 处理冲突的方式使用的是链地址法。1
2
3
4
5
6
7
8
9
10 //哈希数组
transient Node<K,V>[] table;
//节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; //可构成链表
}
每个节点都包含下一个节点的引用。链表虽然实现简单,但是在查找的效率上只有 O(n),而 HashMap 大部分的操作都是在进行查找,如果链表变得越来越长,这个查找的效率就非常差。Java 8 对其实现了优化,链表的节点数量在到达阈值时会转化为红黑树,这样查找所需的时间就只有O(log n)。
红黑树 就是平衡二叉查找树
这就是对阈值的介绍,当链表的长度大于阈值就会转为红黑树,如果小于阈值就转为链表。1
2
3
4
5
6
7
8//链表的节点大于这个值就进行树化
static final int TREEIFY_THRESHOLD = 8;
//树的节点太少就转为链表
static final int UNTREEIFY_THRESHOLD = 6;
//数组长度大于这个值才进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
1 |
|
数组扩容
HashMap 避免冲突的另一种方式就是对散列表进行动态扩容。
所谓扩容,其实就是用一个容量更大(在原容量上乘以二)的数组来替换掉当前的数组,这个过程需要把旧数组中的数据重新hash到新数组,所以扩容也能在一定程度上减缓碰撞。
table 数组的大小约束对于整个 HashMap 都至关重要,为了防止传入一个不是2次幂的整数,必须要有所防范。tableSizeFor()函数会尝试修正一个整数,并转换为离该整数最近的2次幂.
1
2
3
4
5
6
7
8
9static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap通过负载因子(Load Factor)乘以 table 数组的长度来计算出临界值,算法:threshold = load_factor capacity。比如,HashMap 的默认初始容量为 16(capacity = 16),默认负载因子为 0.75( load_factor = 0.75),那么临界值就为threshold = 0.75 16 = 12,只要 Entry 的数量大于12,就会触发扩容操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
....
// 默认的阈值
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
...
threshold = newThr;
...
}
return newTab;
}
从上面解释可以看出,负载因子越小,数组就越小,查找的性能就会越高,但同时额外占用的内存就会越多,因为需要经常扩容。
扩容后的下标
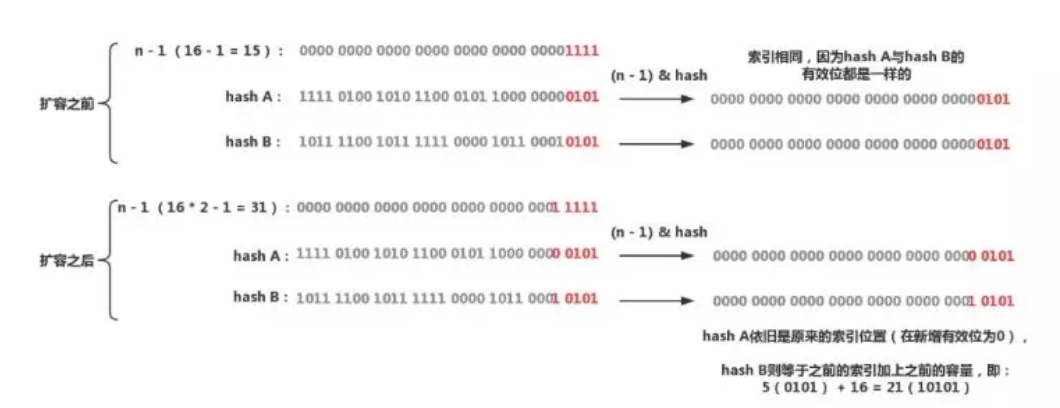
扩容后的下标需要依靠两个前提条件:
- 数组是永远长度是 2 次幂的.
- 扩容前的下标是 (n-1)& hash .
前面说过 n-1 就像一个掩码,现在数组增加一倍,在进行 & 操作的时候 n-1 就增加了一位,因此只要判断 hash 和新增加的有效位是 0 还是 1 就可以确定新的位置,如果是 0 就不变,如果是 1 ,索引就是原索引加上扩容前的容量。通过这种方式就可以将本来在 扩容前冲突的两个节点拆分到新的数组,在扩容的时候均匀地散开。
四.TreeMap
TreeMap 是一个基于红黑树的有序的 Map ,继承自 AbstractMap 抽象类,实现了 NavigableMap 接口,这个接口又继承了 SortedMap 。
SortedMap
1 | public interface SortedMap<K,V> extends Map<K,V> { |
这个接口定义就是对 Map 的元素的排序,以及几个子视图,比如 从 from 到 to 的视图或者从 from 到结束或者从开始到 to 的视图。
NavigableMap
NavigableMap 对 SortMap 进行了扩展,增加了对键值对的导航方法,和一些以逆序升序排序的集合视图。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63public interface NavigableMap<K,V> extends SortedMap<K,V> {
//返回比 key 小的键值对
Map.Entry<K,V> lowerEntry(K key);
K lowerKey(K key);
Map.Entry<K,V> floorEntry(K key);
K floorKey(K key);
Map.Entry<K,V> ceilingEntry(K key);
K ceilingKey(K key);
Map.Entry<K,V> higherEntry(K key);
K higherKey(K key);
Map.Entry<K,V> firstEntry();
Map.Entry<K,V> lastEntry();
Map.Entry<K,V> pollFirstEntry();
Map.Entry<K,V> pollLastEntry();
NavigableMap<K,V> descendingMap();
NavigableSet<K> navigableKeySet();
NavigableSet<K> descendingKeySet();
NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive);
NavigableMap<K,V> headMap(K toKey, boolean inclusive);
NavigableMap<K,V> tailMap(K fromKey, boolean inclusive);
SortedMap<K,V> subMap(K fromKey, K toKey);
SortedMap<K,V> headMap(K toKey);
SortedMap<K,V> tailMap(K fromKey);
}
TreeMap
对于 TreeMap 返回的子视图,都是由两个内部类提供,对这些集合视图的修改同样会影响 TreeMap。1
2
3
4
5
6
7
8
9/**
* 升序
*/
static final class AscendingSubMap<K,V> extends NavigableSubMap<K,V> {}
/**
* 降序
*/
static final class DescendingSubMap<K,V> extends NavigableSubMap<K,V> {}
TreeMap 之所以能够排序是因为内部使用的是红黑树的数据结构,红黑树就是一种平衡二叉查找树,节点使用一个 boolean 型表示。
1 | private transient Entry<K,V> root; // 根节点 |
五.LinkHashMap
LinkHashMap 是一个用链表维护 Map 元素添加顺序的 Map .1
2
3
4
5
6
7
8
9
10
11
12public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{}
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap 继承 HashMap 并实现了 Map 接口,Entry 也继承了 HashMap.Node ,不过增加了 两个节点,before, after 用于将键值对构建成一条双向的链表。
LinkHashMap 同时增加了一个对顺序的标记位。1
2
3
4
5// 这个标记位表示的是遍历元素的模式
// true 表示按最近最多访问的顺序
// false 表示按插入的顺序
// 默认是 false
final boolean accessOrder;
LishHashMap 可以说是结合了 HashMap 查找元素的优点和链表遍历元素的快捷优点,牺牲了获取元素和删除元素维护链表性能。
LishHashMap 并没有重写 put 方法,说明对 put 方式,两者的方式基本是一样,不过是构造节点 newNode 的时候进行前后节点的关联。1
2
3
4
5
6
7
8
9
10private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
而对于 get 方法,如果 accessOrder 标记位指定的是访问模式,还需要将最近访问的节点调整到链表的最后。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e); //调整这个节点的位置
return e.value;
}
//将这个节点调整到链表的最后。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
遍历的时候就直接使用链表的形式进行遍历1
2
3
4
5
6
7
8
9public void forEach(BiConsumer<? super K, ? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
因此对于 LinkHashMap 的遍历,时间与元素的数量成正比,而 HashMap 则是与 table 数组成正比。且 LinkHashMap 还支持按访问顺序排序,因此可以简单地运用成最近使用的缓存策略。
六.ConcurrentHashMap
前面的 Map 都是属于非线程安全的 Map ,可以通过 Collections.synchronizedMap(Map<K,V> m) 转换成一个线程安全的 Map1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
这种方式就是通过 synchronized 将原本的 Map 进行包装而已,锁住的一整个 Map ,同一时间只能只有一个线程访问,性能极差。
java 8 的 ConcurrentHashMap 则是作为线程安全的最优实现。因为目的是在多线程的环境下使用,因此各个方面就需要考虑多线程的问题。
1.初始化
ConcurrentHashMap 的初始化时 懒加载的,只有在 put 操作的时候才进行初始化。
为了避免多次初始化,使用了变量 sizeCtl 用于控制 table 数组的初始化和扩容。
1 | private transient volatile int sizeCtl; |
它的值代表如下集中情况:
- -1 ,表示 table 正在初始化或者扩容
- -(1+n) ,表示有 n 个线程在进行扩容
- 大于 0:
- table 还未初始化,就表示初始化的数组大小
- table 初始化了就表示,触发扩容的阈值。
1 | private final Node<K,V>[] initTable() { |
sizeCtl 是一个 volatile 变量,只要有一个线程 CAS 操作成功,sizeCtl 就会被暂时地修改为-1,这样其他线程就能够根据 sizeCtl 得知 table 是否已经处于初始化状态中,最后 sizeCtl 会被设置成阈值,用于触发扩容操作。
2.扩容
对 talbe 的扩容并没有选择直接加锁,而是选择了基于 CAS 的并发同步策略,将table 作为一个多线程共享的任务队列,让多个线程同时协助扩容。这个时候只需要在原来的 table 数组上维护一个指针表示数组下标,当一个线程进行数据迁移的时候,就先移动指针。1
2
3
4/**
* The next table index (plus one) to split while resizing.
*/
private transient volatile int transferIndex;
3.get
1 |
|
因为 get 只要保证访问 table 与节点的操作总是能够返回最新的数据就可以了。ConcurrentHashMap 并没有采用锁的方式,而是通过 volatile 关键字来保证它们的可见性。虽然 volatile 不保证原子性,但是 ConcurrentHashMap 只是用来确保访问到的变量是最新的,所以也不会发生什么问题。
4.put 和 remove
ConcurrentHashMap 对锁的粒度只是针对每个 table 元素,对节点进行操作的时候需要通过CAS 和 互斥锁保证线程安全,只对需要操作的这个 table 元素加锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//这里是无限循环
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 这里是 CAS 插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果失败的话才进行 加锁
...
synchronized (f) {}
...
}
1 | public V remove(Object key) { |
对于 put 操作时先使用 CAS 尝试修改,如果有线程竞争才去通过 加锁,而对于 remove 因为一次需要删除多个,所以是直接加锁。
5.计数
1 | private transient volatile long baseCount; |
1 | /** |
ConcurrentHashMap 的计数方式使用两个变量进行协助。
在一个低并发的情况下,就只是简单地使用 CAS 操作来对 baseCount 进行更新,但只要这个 CAS 操作失败一次,就代表有多个线程正在竞争,那么就转而使用 CounterCell 数组进行计数,数组内的每个 ConuterCell 都是一个独立的计数单元
每个线程找到自己对应的位置方式类似于 Hash 散列算法,但是这也代表着还是会产生竞争,因此还使用了自旋锁的方式,无限循环加上CAS 来模拟出一个自旋锁来保证线程安全,自旋锁的实现基于一个被 volatile 修饰的整数变量,该变量只会有两种状态:0 和 1,当它被设置为 0 时表示没有加锁,当它被设置为 1 时表示已被其他线程加锁。这个自旋锁用于保护初始化 CounterCell、初始化 CounterCell 数组以及对 CounterCell 数组进行扩容时的安全。
最后的统计就只需要 将每个 CounterCell 和 baseCount 进行相加就行了。